



Wordle has taken the world (and Crayon Data) by storm. I’m not an expert in English vocabulary. But I am good with data science! And so, I approached the problem of solving Wordle using my expertise. With due credit to 3Blue1Brown for the inspiration.
How do people generally approach the problem of finding the five-letter word of the day?
I asked a Wordle enthusiast, who uses this algorithm:
- First choice of word should cover 3 vowels + P + S
- Based on the feedback, filter the possibilities
My logic of selection of the word is as follows:
- Choose the letter that has highest probability of occurrence as a first letter
- A second letter that has highest probability of occurrence given the first letter
- The third letter that has highest probability of occurrence given the first two letters
- Select the word with the first 3 letters
- In case of more than 1 word, use random selection with uniform distribution to select one among the identified words
I curated a sample of 16,000 five letter words. From this list, we get the probability of occurrence of letters in each position.
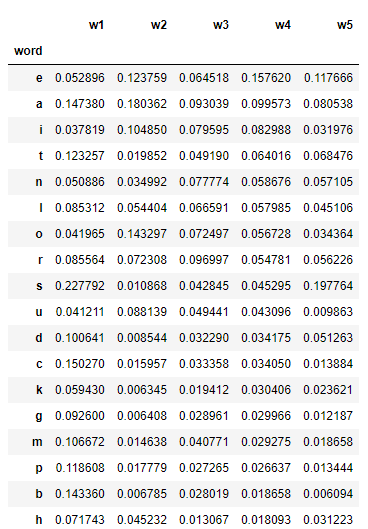
It was noticed that the letters S, C, A, B, and T are the top 5 characters that will give greater information about the word to find.
Having selected the first character, the subsequent characters are determined based on the principle of Bayes’ Theorem.
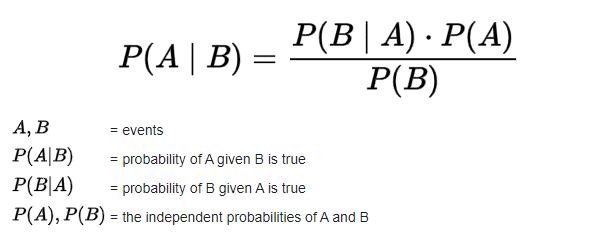
This builds a probability matrix like the one below:
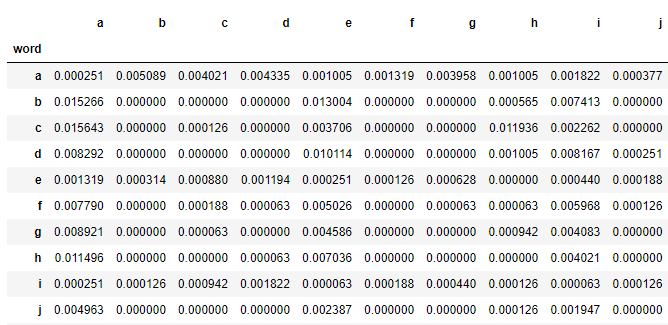
A similar probability matrix was built for other positional parameters as well.
Now, to play the game, the initial seed was selected at random.
This seed was then passed on to the model to get the initial word. The word was evaluated with the game. The game provides 3 outputs (Grey, Green and Yellow). The result is passed on along with the initial word to the model as feedback. The model returns another word based on the feedback received. This process continues until the word is found or the limit is reached. So far, the model can identify the word within the given number of iterations i.e., 6.
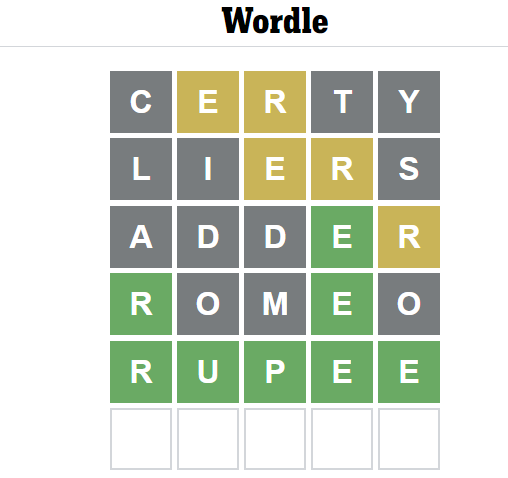
Consider the initial word given is “certy” and assume that today’s word is “rupee”.
In this case, the first iteration gives two characters E and R. They are present in the word, but the position is wrong. The feedback to the model will be “Grey, Yellow, Yellow, Grey, Grey”. Now we have a list of words to eliminate that contains the characters C, T, and Y.
Assume the next iteration produces a word “liers”. The feedback in this iteration will be “Grey, Grey, Yellow, Yellow, Grey”. In this iteration, our elimination character adds L, I, and S. The total number of characters eliminated is 6. The third iteration word is “adder”. The feedback in this iteration is “Grey, Grey, Grey, Green, Yellow”. Now we have rightly identified the fourth character. The fourth iteration word is “romeo”. The feedback for this word is “Green, Grey, Grey, Green, Grey”. The word starts with “r” and fourth character is “e”. The fifth iteration word is “rupee”. Bam! This is the word that we are looking for!
The approach mentioned above seems to be more intuitive. However, there is a deep-rooted information theory behind this. Stay tuned for a I shall write the theoretical background in a separate post.



