


Disclaimer: This piece of writing is meant to drive the case for social distancing and self-quarantines. It isn’t meant to cause panic. I’m in no way an expert, in neither epidemiology nor mathematical modeling. The approach undertaken below is laden with assumptions, both known and latent in nature. This is an opinion piece and not an advisory on public policy.
November, 2019: People in the wet market in the city of Wuhan, an oft-forgotten city in the Chinese province of Hubei, go about their business for the day, knowing little of the havoc that’ll shortly be unleashed on the world.
Fast forward to March, 2020.
The new year has come and gone, and with it the first stories from China of a new pathogen the likes of which the world has never before seen: Covid-19.
Sweeping through the continental mass of China, it has now spread all over the planet, almost as if taken from a dystopian novel.
As it reaches the shores of India, the country of my residence, I cannot help but feel a little scared and worried. The stories that come out of affected countries are dire, dreary and desperate. At the time of writing this article, Italy faced one of its worst days yesterday (20th March, 2020), when close to 700 people succumbed to the vile virus in a single day.
I must admit, I did not take the threat seriously, much like so many other people in my age group. The argument below was commonly heard at the lunches, in the corridor conversations, and on the Whatsapp groups.
“Oh, so what if it infects a lot of people… only like 2% die. That’s so much lower than MERS or H1N1 or even the common flu. Why are we worrying about this?”
In hindsight, what was commonly overlooked in the argument was that this was heavily confounded by the age of victims.
Statistical theory tells you to be cautious with the numbers. Be prudent with the numbers. Be patient with the numbers.
You always need to coax the numbers to give insights.
The older one gets, the higher the mortality rates. And significantly higher at ages more than 65.
Covid-19 is a boomer-killer.
Much like the average 20-something Indian, I used to spend most of my childhood summers at my grandparents’ place, and I have a lot of cherished memories of those summers, and of them. For the longest time, because of their constant presence, I was convinced that they’re invincible. That they will always be there. And now, for the first time, I’m afraid.
I’m very afraid.
So much so, that for the past week or so, I’ve been brushing up on the theory of epidemiology. From May’s 1982 paper where the fundamental, basic reproduction number, Rₒ, was introduced to the more recent work by Diekmann, Odo, Hans Heesterbeek, and Tom Britton¹ on formalizing the definition and properties of Rₒ.
This piece of writing looks at adopting a disease model that gives insight into how social distancing and quarantining helps.
And it does, quite considerably.
Modeling Covid-19: Disease Impossible (Or is it?)
The following section can get quite dry because of the mathematical nature of the system. I’ll try my best and keep the content as concise as I can. However, not all of the math can be filtered, so please bear with me.
What we’ll do in this section is to try and fit the model for the data shared for Germany. The same analysis can be replicated for other countries, provided the data is available publicly and without concerns of sampling bias and representation bias.
At this juncture, it’s vital to reiterate the fact that this analysis and the findings are in no way an accurate picture of reality simply because of the various assumptions that are rendered void in real life.
At the end of the day, this analysis should urge the reader to practice social distancing and stay at home. And be proud, and satisfied with taking such a decision.
In modeling Covid-19, we aren’t modeling individual likelihoods. We don’t have sufficient publicly available data for that. What we are attempting is to model the population under the behavior of the contagion.
While there is an entire spectrum of models out there (R: earlyR, EpiEstim), the model we’ll implement is the simplest of them all. The more complex the model, the more assumptions are baked into the interior workings; in the current case of a rampant, life-threatening pandemic I am not making any assumptions that I don’t fully understand.
The model we adopt is called the SIR model². First discussed in the Royal Statistical Journal in 1927, it is a dynamic model that compartmentalizes the population/junta into three broad groups:
- Susceptible: Any individual who doesn’t have the infection but can get infected is considered susceptible
- Infected: Any individual that has the infection, and is transmitting the disease, is considered as infected
- Removed: Any individual who’s not in the Infected or Susceptible classes because of recovery, isolation or death is considered removed
A key assumption in this model is that infection guarantees future immunity. So something like a flu cannot be modeled using the SIR framework, while chickenpox, and measles can. As of now, Covid-19 hasn’t shown any behavior where recovered patients have relapsed.
Further, we don’t make any assumptions on the population vitals. These are the birth rates, and death rates due to causes other than Covid-19.
The movements from one group to another are governed by a set of differential equations.
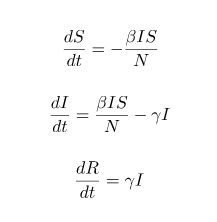
Movement of states under the SIR model
These equations are important because of the parameters they solve for.
β, γ are the two most important elements in this model.
- β controls the contact rate or the average number of contacts that turn out to be infected for every infected individual per day
- γ controls the removal rate or the proportion of people recovering/dying/isolating on a daily basis
In the recent public policy terms,
- β is the parameter that controls your social distancing(lower beta, fewer contacts)
- γ controls your self-quarantine strategy(higher gamma, lower period of infectivity)
- Together, Rₒ = (β / γ) ∝the number of secondary cases for every primary case
If there’s anything you should remember at the end of this, it’s this.
Lower your beta, and increase gamma. Period.
You solve those equations, and you get to understand how the disease will develop.
Now, I can hear you saying “enough of the theory… Where’s the actual model dude?”
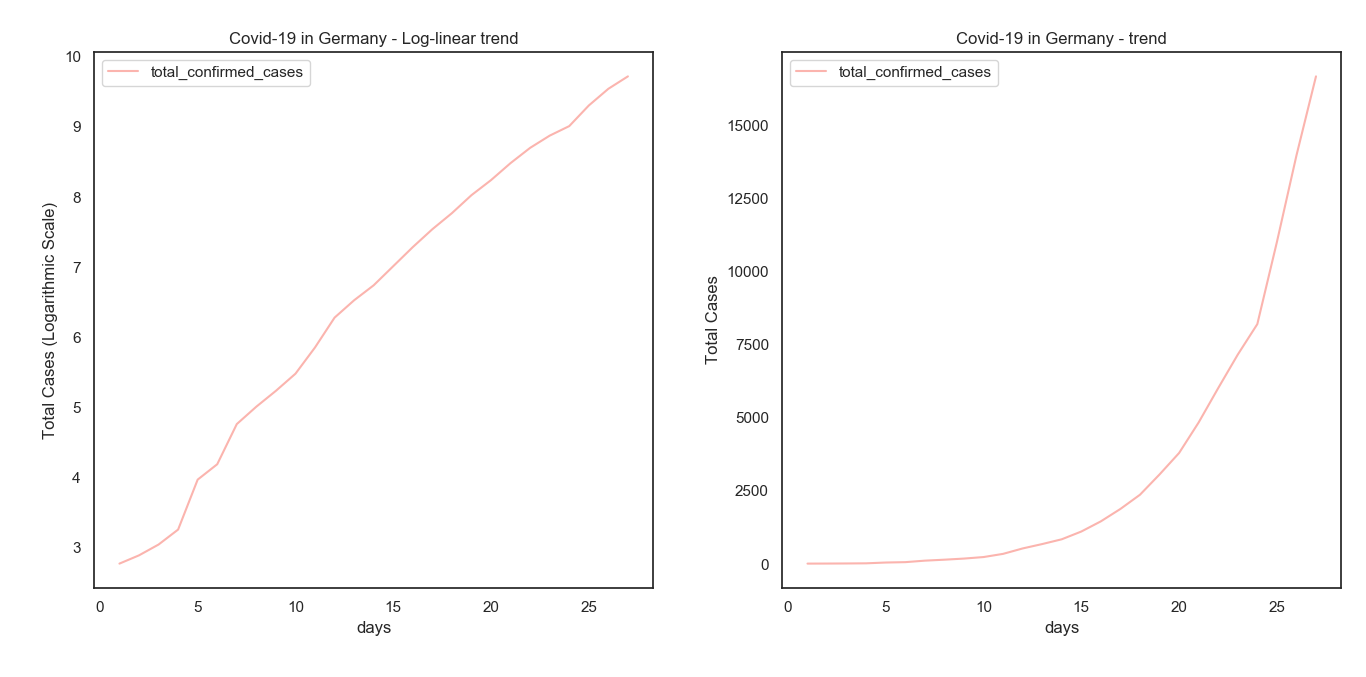
We extract the data for Germany, because their’s seemed to be the best maintained (by the Robert Koch Institute), by running a simple python script that extracts it from their Wikipedia page. Other countries considered were Italy, and the US.
Note: The data for India is incomplete, and there are concerns regarding sufficient testing in the country. Spain has incomplete data for certain days.
Ditching the time-series index, we adopt the notation of days since the first day. Let’s plot the data.
Using Python’s scipy module, we solve for the ODEs and get estimates for β and γ.

Let’s evaluate model fit after making predictions for the next ~50 days (amounting to 80 days in total).
We get an RMSE of 625, and MAPE (mean average percentage error) of 23%.
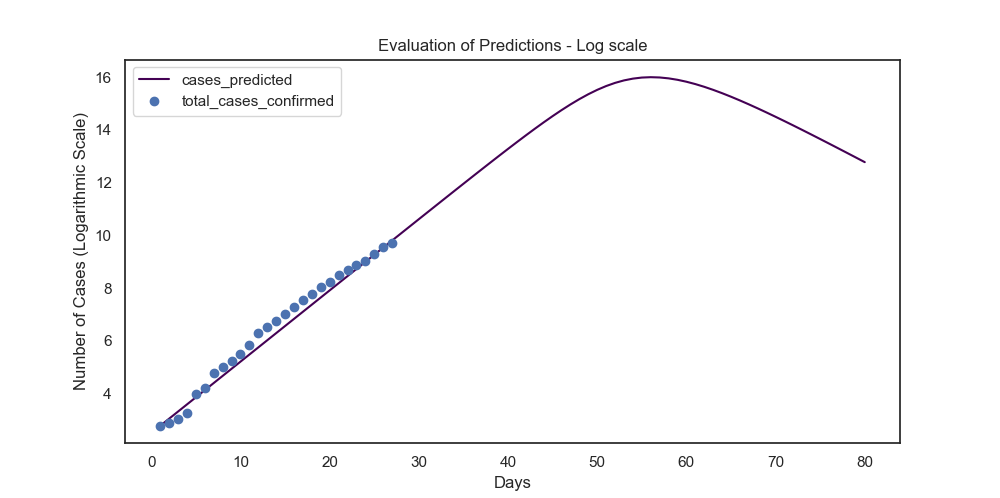
Considering that the model fit is not too bad, what can we tell?
- Rₒ = 1.9 ≈ 2
- β = 0.65
- γ = 0.35
This is slightly off compared to WHO estimates of 2 to 2.5.
Germany’s federal public health organization that monitors infectious diseases, the Robert Koch Institute, estimates that the basic reproduction number of Covid-19 is between 2.4 and 3.3.
Conventional disease study says that if the Rₒ > 1, then the disease should be considered an epidemic. (Duh)
So what now?
How to control Rₒ?
If you recall what was mentioned in the previous section, there are two ways to cut down on Rₒ:
- β must be reduced. This is more straightforward to analyze and simulate.
- γ must be increased. This is more difficult to do, because you’re playing with the period of infectivity of the disease.
But before going into why we must reduce Rₒ, let’s plot the all-too-familiar curve.
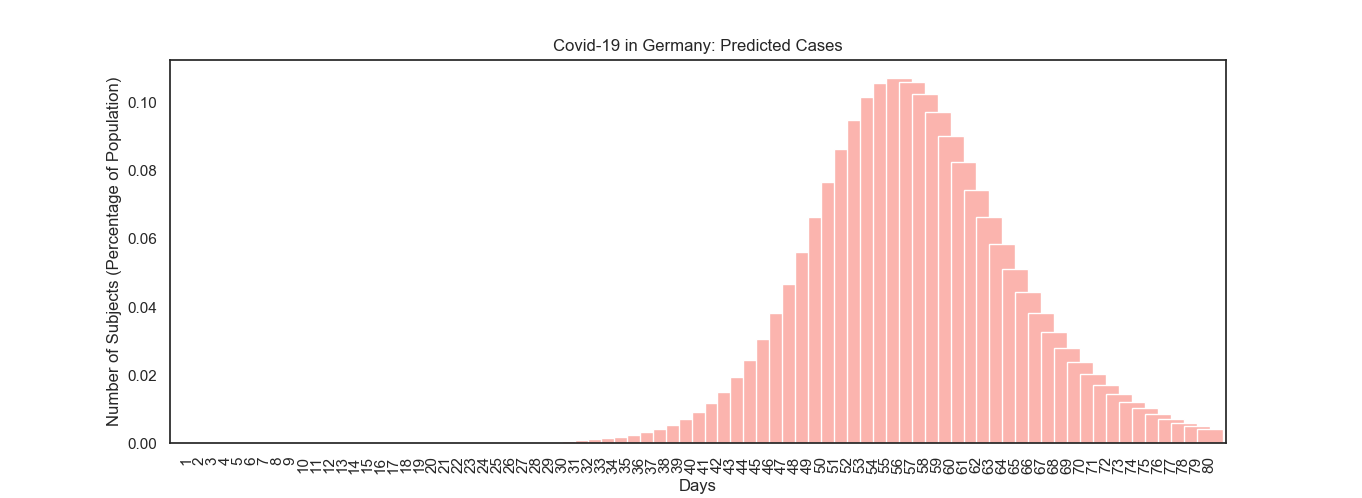
Yes, the infamous Everest from the now-common “flatten the curve” discussions.
Let’s evaluate what would happen if we adopt a simple strategy of distancing ourselves. Say, some social distancing intervention was done in Germany today such that the contact rate was reduced by 50% for the next n days, following which, it lapses to a more cautious reduction of 20%. In other words
- β = βₒ if t < 21st March, 2020
- β = 0.5βₒ if t ≥ 21st March, 2020 and t < n days from 21st March
- β = 0.8βₒ if t ≥ n days from 21st March
Now, we can change n for various configurations such as: 7 days, 14 days.
When I ran this simulation, the way the model behaved blew my mind.
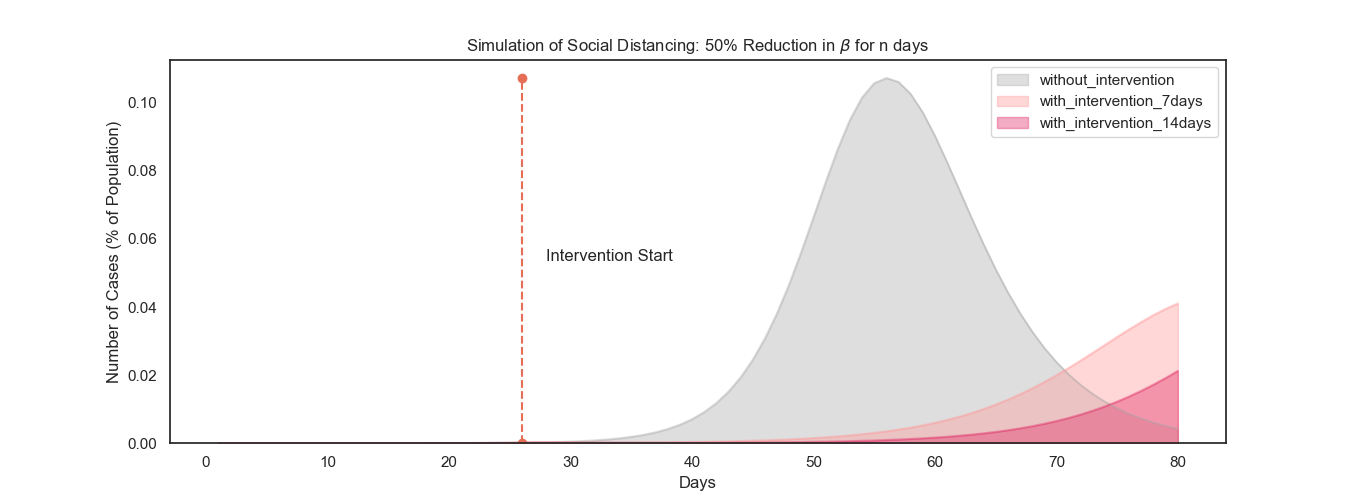
The curve flattens!
Nowadays, one of the most hotly debated components of these interventions is the timing. In the above simulation, we are enabling a 50% reduction in contact rate from the current day, i.e., 21st March, 2020. On the graph, this is day 26.
What would happen if this were to take place in the peak of the epidemic, say day 40 when close to 2% of the population is infected?
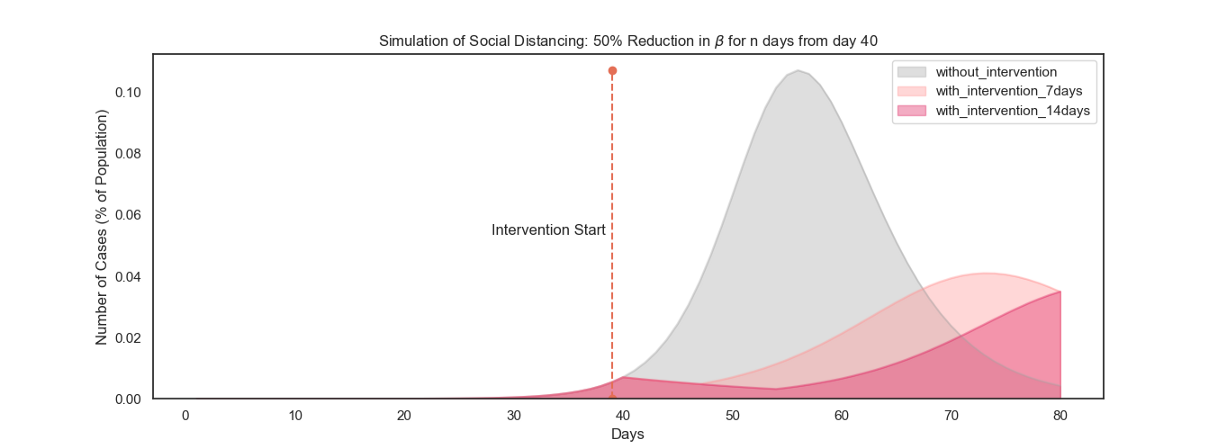
Voila!
2% might not seem much, but this is against the entire population of Germany. A meager 2% amounts to 1.6 million people.
Hence, early interventions are good when it comes to Covid-19.
One thing to note from the visualizations above is that as the intervention takes place and the number of infections drop, the number of susceptibles remains large. This would mean exercising greater caution once the intervention is over. A slight lapse on the β, as simulated above, can lead to significant growth in infections, again.
This is a fairly simple strategy, dependent only on time.
If data for different ages were available, strategies for age groups and demographic segments could be formed and tested in the form of simulations.
Summary
In summary,
- Social distancing is good, but better when done early.
- Quarantining yourself is good, but better when done early.
- Both of the above are a must in the current times for at least 14 days, to reduce the strain on the healthcare system.
It is just not worth the risk to mingle with people until the situation comes under control.
As a final note, it’s important to call out the fact that this analysis is purely illustrative. Sure, we used actual data, and fit the model to it. But disease modeling has so many more nuances that I don’t have the expertise on. Moreover, in view of this outbreak, there have been questions on the quality of the data considering the frequency of the tests.
These are biasing factors that affect the sample, and one must be cognizant of them.
The simple SIR model used in this post suffers from a number of limitations. However, at the large scale of the outbreak we are now talking about, this simplification appears acceptable.
Further, it assumes homogeneous mixing between individuals, which is way too simple. One could, for instance, divide the population into age groups, along with their locations and model the interactions between them. That might give a more realistic reflection of how the population is shaped.
Again, for the purpose of the visualization of the flatten-the-curve effect, I think a simple model is alright.
The insight from here isn’t that the model has predicted it all and we’re all doomed. No model is ever correct.
Instead, focus on how critical social distancing is. Focus on how self-quarantining can help. Flatten the curve.
Stay home, stay safe.
This article was originally published on Medium. You can check it out here.



