




In a data-driven world, it is critical to manage large chunks of data in a simple way. In the words of comedian Dave Chappelle…

This is where solutions like vector databases come in. They are significant because of their ability to efficiently store and process high-dimensional data representations. According to a report by PwC, the contribution of artificial intelligence to the global economy could reach $15.7 trillion. In the era of AI, applications like vector databases are in the scope of immense growth and can rapidly reach their potential in the coming years.
What is a vector database?
A vector database is a powerful tool and database management system (DBMS). They are the architects behind the seamless translation of diverse data types, including text and images, into a coherent numerical language understood by machines. By converting this data into numerical vectors, vector databases empower AI models to not only analyze but also glean valuable insights from the information at hand.
Simply put, it converts unstructured data – words, sentences, other pieces of information – into numerical representations called vectors. These vectors capture the core of what the original data is all about in a compact and organized way. Translating words and sentences into a language that computers can understand helps in processing and analyzing data more effectively.
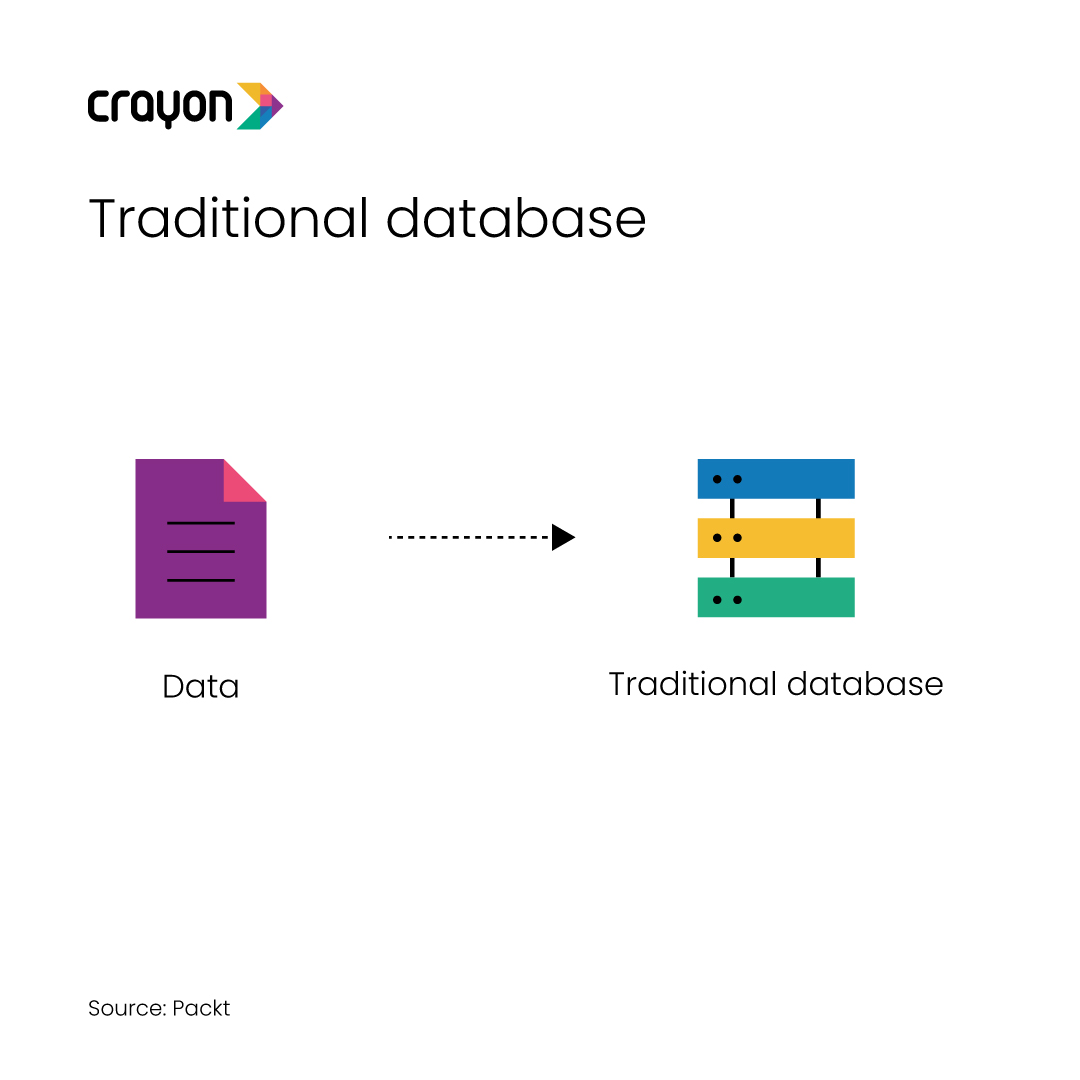
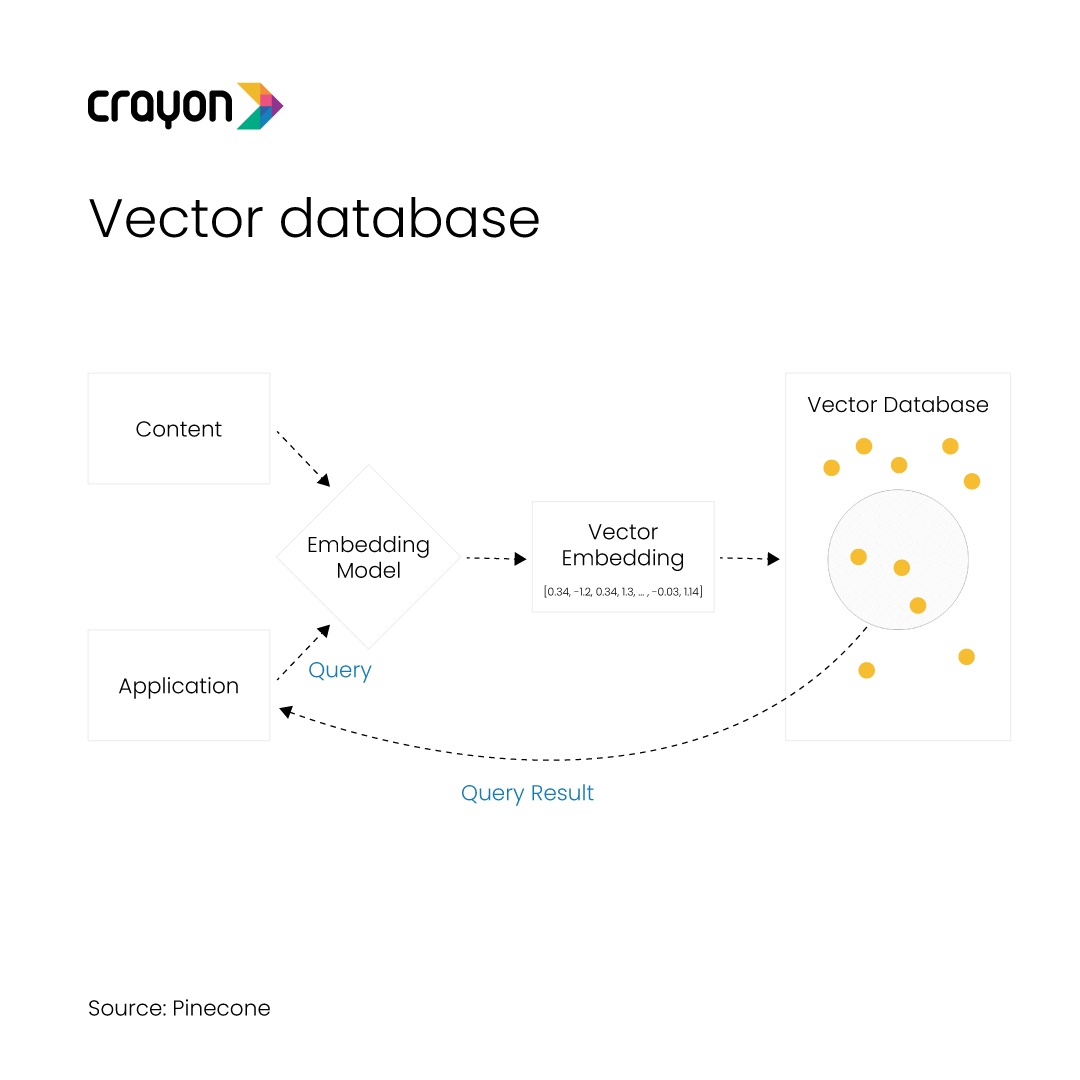
The significance of vector databases in AI
In the dynamic realm of AI, data lies at the heart of innovation. Data drives the capabilities of AI models to new heights. Particularly in the domain of Natural Language Processing (NLP), the challenge lies in transforming complex and unstructured data into a format that AI models can comprehend and manipulate effectively. This is where the transformative role of vector databases emerges.
Here are a few ways in which it is being used.
Representation of data: AI models, especially in NLP, require data to be represented in a format that machines can understand and process. Vector databases convert text, images, and other forms of data into numerical vectors, making it easier for AI models to analyze and learn from the data.
Word embeddings: These are a type of vector representation used to capture the semantic relationships between words. These embeddings are widely employed in NLP tasks like sentiment analysis, machine translation, and text classification.
Machine learning with numerical data: Vector databases facilitate the training and deployment of AI models that use machine learning algorithms by transforming non-numeric data into numerical vectors.
Information retrieval: Vector databases enable quick search and retrieval of relevant information based on vector similarities. For example, search engines use vector databases to find relevant documents for a given query.
Multimodal AI: This is where AI models process and understand information from multiple modalities, such as text and images. Vector representations of different modalities allow AI systems to integrate and fuse information for more comprehensive decision-making.
Transfer learning: Involves leveraging pre-trained AI models to tackle new tasks with limited data. Vector databases store pre-trained model parameters, making it easier for AI models to benefit from previously learned knowledge.
Dimensionality reduction: In some AI tasks, the data may have high dimensionality, which can be computationally expensive. Vector databases often employ dimensionality reduction techniques to compress data while preserving its essential features.
Recommendation systems: AI-driven recommendation systems benefit from vector databases as they enable the efficient comparison of user preferences and item characteristics. The system can quickly find similar users or items by representing users and items as vectors. Like when you see “Customers who bought this item also bought…” online. Companies like Netflix and Spotify use vector databases to power their personalized recommendation engines.
Topic modelling: Vector databases assist in grouping similar documents or texts based on their vector representations, allowing the identification of common themes or topics within a large corpus of text data.
Data Compression: By representing complex data in compact vector form, vector databases enable data compression, making it easier to store and manage more efficiently.
The efficacy of vector databases for NLPs
The ability of vector databases to transform unstructured data into a compact and meaningful numerical format enables a wide array of NLP tasks and applications. They have revolutionized the field and are crucial to modern NLP systems.
Here are some examples to illustrate their efficacy:
- Word similarity: In vector databases, words are represented as vectors, allowing us to measure their similarity. For example, the vectors for “dog” and “cat” will be closer together than “dog” and ” car.” This is important in various applications, such as autocomplete suggestions in search engines.
- Text classification: In sentiment analysis or spam detection, vector databases transform text data into numerical vectors, allowing machine learning models to classify and categorize texts effectively. This is how email providers detect spam emails and how social media platforms analyze sentiments in user posts.
- Image similarity: Vector databases can convert images into numerical vectors. These vectors capture visual features, enabling image similarity searches. For instance, a vector database can quickly find similar images to the one you upload in an image database.
- Language translation: Vector databases are used in machine translation tasks, where sentences in one language are represented as vectors and then translated into another language using these vector representations. This is the basis for many translation services in today’s market.
- Clustering and grouping: Vector databases group similar data together. For example, similar news articles can be clustered based on their vector representations in a news article recommendation system.
Types of vector databases
While there are several vector databases in the market and gaining quite a traction, the most notable and popular players are as follows:
 Milvus: Originally developed by Zillz, it’s an open-source vector database mainly designed for high-performance similarity search. It has gained a thriving user base mainly due to its scalability and supports a variety of vector similarity search algorithms, including Euclidean distance, cosine similarity, and LSH. Milvus is scalable to large datasets and can perform similarity searches on vectors in milliseconds.
Milvus: Originally developed by Zillz, it’s an open-source vector database mainly designed for high-performance similarity search. It has gained a thriving user base mainly due to its scalability and supports a variety of vector similarity search algorithms, including Euclidean distance, cosine similarity, and LSH. Milvus is scalable to large datasets and can perform similarity searches on vectors in milliseconds.
- Use cases and purpose: Search, recommendation, fraud detection. High performance and scalability
- Architecture and storage: Distributed, columnar, and in-memory
- Querying and indexing: Euclidean distance, cosine similarity, and LSH
- API and integration: RESTful API
![]() Pinecone: Pinecone was developed by Pinecone Systems, a company founded in 2019 by Edo Liberty. This vector database is a managed service for real-time search and recommendation applications. It is a closed-source vector database that is offered as a cloud service. It offers a simple, intuitive interface making it developer-friendly, and hides the complexity of managing the underlying infrastructure. It is mainly suitable for applications that require real-time performance, such as search and recommendation.
Pinecone: Pinecone was developed by Pinecone Systems, a company founded in 2019 by Edo Liberty. This vector database is a managed service for real-time search and recommendation applications. It is a closed-source vector database that is offered as a cloud service. It offers a simple, intuitive interface making it developer-friendly, and hides the complexity of managing the underlying infrastructure. It is mainly suitable for applications that require real-time performance, such as search and recommendation.
- Use cases and purpose: Real-time search, recommendation, and performance
- Architecture and storage: Distributed and in-memory
- Querying and indexing: Euclidean distance, cosine similarity, and LSH
- API and integration: RESTful API
 Weaviate: An open-source vector database developed by SeMI Technologies, it is a graph system that manages and queries vector-based data with semantic relationships. Its ability to perform semantic searches and handle real-time updates makes it suitable for various applications, including knowledge graphs, recommendation systems, and semantic NLP. It also supports a variety of vector embeddings so that you can use it with various machine-learning models.
Weaviate: An open-source vector database developed by SeMI Technologies, it is a graph system that manages and queries vector-based data with semantic relationships. Its ability to perform semantic searches and handle real-time updates makes it suitable for various applications, including knowledge graphs, recommendation systems, and semantic NLP. It also supports a variety of vector embeddings so that you can use it with various machine-learning models.
- Use cases and purpose: Search, recommendation, knowledge graph. Flexibility and scalability
- Architecture and storage: Distributed, columnar, and in-memory.
- Querying and indexing: Euclidean distance, cosine similarity, and LSH
- API and integration: GraphQL API
In summary, vector databases are a crucial bridge between raw data and AI models. Handling unstructured data with sheer volume makes it a unique and impressive tool that supports strategic business decisions. While there are several complexities with this relatively new technology along with the cost and challenges concerning the type of data quality, vector databases continue to gain popularity.
In a world that’s irreversibly data driven, vector databases aren’t going anywhere.



