


Historically, it has been a struggle for enterprise software vendors to control the deployment environment on their client’s installation base. Without proper control on the deployment environment, troubleshooting any issues on the client’s setup was a nightmare.
Initially, companies delivered an appliance with a customized OS image as part of it. That gave complete control on the environment right from hardware to OS and through software applications installed as part of it. But it resulted in harder problems for businesses to solve. Enterprise software vendors had to form partnerships with other companies and rely on these companies, to ship the hardware platform for them. They had to search for multiple partnerships to avoid getting locked in with one partner.
Server Virtualization
Server virtualization came to the rescue with a multi-vendor hardware platform and environment issues. It helped enterprise software vendors to launch their software effectively, by testing and certifying on top of a handful of hypervisors. It gave a nice abstraction on top of which, the enterprise software applications can be developed and tested. In the organization I worked at earlier, we used to generate ova images that can be used to create VM instances on top of hypervisors, which could help to create the same effect of a completely closed appliance that is much easier to manage.
There were couple of issues that this model couldn’t address. The first, to build an ova image, you need to have immense system level knowledge. The second is with managing distributed environments. When a software demands distributed installation across multiple nodes, there is still a lot of manual work involved in bringing up these multiple VM’s(Virtual Machine). As enterprises started to use cloud as their infrastructure, managing a distributed environment becomes more critical, irrespective of the nature of the application (i.e. even when the application runs within a node).
Docker
Docker steps in to precisely address these two issues. Docker allows anyone to quickly create, launch and test Docker containers very easily. When it comes to distributed Docker management there are lot of frameworks like, Google’s kubernetis, CoreOS, Multi-Container orchestration, etc. that come in handy with Dockers.
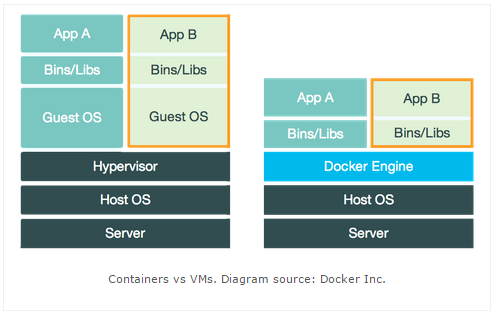
Along with these, Docker is very lightweight when compared to a VM. As illustrated below, it avoids an additional layer of a hypervisor and runs a really lightweight Docker engine. It supports Windows as well as Boot2Docker.
Difference between a VM and Docker:
How we chose our data processing stack
Though Docker attempts to solve many issues, we chose the aspect of “building consistent environments that are easy to replicate”.
Initially at Crayon, during our development cycles, to test a minor code we had to make changes to our MapReduce programs. We had to move our programs to the production cluster in the AWS environment. It was mainly due to the time and effort involved in setting up the Hadoop environment locally to test. When a POC needed to be done only with some components on Hadoop ecosystem then setting up the system time and again was be a productivity loss — as the number of components on Hadoop ecosystem was growing.
We started our journey with automated Hadoop cluster launch provided by SequenceIQ. Within few minutes we could bring up a multi node Hadoop cluster. They had an interesting way to abstract the cluster configuration in the forms of blueprints and automating cluster setup and launch with the help of Dockers. Hortonworks acquiring SequenceIQ shows the importance of the kind of work what SequenceIQ did with automated Hadoop cluster deployment.
SequenceIQ inspired us to adopt Docker. We made quite a bit of progress by customizing and tweaking the SequenceIQ Docker image. We built an entirely Dockerized platform for our data processing.
For all our POCs with Hadoop components we have created consistent and easily replicable Docker instances. Instead of people trying to install every single component from the Hadoop ecosystem, required for their development or testing environment, we can just create it once and use it any number of times and everywhere.
This was the start of our journey to reach consistent development, testing, integration and deployment in a way that is seamless. We look forward to make Docker our default artifact until the phase of deployment. Though there may be challenges in an enterprise environment, we hope that there will be an industry wide adoption of Docker. Stay tuned for a detailed article on our approaches and achievements so far.
October 11, 2024



