


British mathematician Clive Humby was spot on with his prediction that “data is the new oil”. It reflects not only the value of data, but also its exhaustible nature.
While the world is still starry-eyed about the power of data, let’s pause for a moment. Is ALL data accessible? As individuals, none of us want to share our personal details, except the ones we choose. And there’s nothing unfair about that. Today, tech is increasingly catering to this need for privacy.
So, if a good part of data remains blanketed by privacy policies, how can enterprises tap into the massive potential that data holds?
Enter synthetic data generation. It is poised to heroically save the day, month, or decade, for that matter.
But doesn’t “fake” data defeat the purpose of using data in the first place?
Ok, here’s the deal. Synthetic data is NOT the same as dummy data.
Dummy data, also known as placeholder data or test data, is fabricated information used for testing, demonstration, or placeholder purposes.
Synthetic data refers to artificially generated data that imitates real-world data patterns and characteristics. It is created using computer algorithms or AI models to simulate the properties and statistical distributions found in authentic data sets. Synthetic data is designed to mimic the structure, relationships, and variability of actual data, but it does not contain any sensitive or personally identifiable information.
Extrapolation is not to be confused with exaggeration.

Most crime or thriller movies feature a scene with a sketch artist creating an image of a suspect based on an eyewitness account. They often produce multiple versions based on the same input.
In a similar fashion, synthetic data generators study available data from all possible dimensions and produce data that reflects the patterns and trends present in the original data.
Why do we need synthetic data?
In this age of AI, synthetic data serves several important purposes. Let’s look at a few key uses.
1. Privacy
Across fields, obtaining raw data is restricted by privacy regulations. Whether retail or healthcare, these concerns are understandable. But analysis is essential to use AI effectively. Case in point: predicting a pandemic or knowing its trendline. Having this information will help authorities take the necessary steps to mitigate any crisis.
Mostly.AI, an Austria-based synthetic data generation organization, faced this challenge. One of Europe’s largest banks wanted to develop a mobile banking app that could truly substitute for in-person banking. However, they could not divulge real transaction data since it is highly regulated. And dummy data could never work for a project of this scale.
Mostly’s algorithm sifted through the available raw data and gave the bank the means to generate any number of synthetic users. The best part: when presented with a mix of synthetic and real users, the product developers could not spot the difference!

2. Access
Measurabl, a US-based ESG (Environmental, Social and Governance) data management solution provides solutions for real estate enterprises. As they scaled up, they faced data accessibility issues. A single environment to test or process the data became infeasible when the number of engineers and projects increased.
To find a way forward, they collaborated with Tonic.AI, a synthetic data generation enterprise headquartered in San Fransisco. Once relevant synthetic data was available, engineers at Measurabl could process their data in local environments. The result: development teams went from working with a mere 10 datasets to being able to produce over 100,000 in no time.
3. Cost
With the growing realization of data’s value, companies across all industries are sure to compete for the best-in-class data. Add that to the fact that original data is limited in quantity. You guessed it right – high procurement costs!
Synthetic data is not free either, but the advantage of an upfront cost associated with synthetic data generation against periodic cost incurred on buying original data is pretty self-explanatory.
4. Time
Once the initial training phase is completed, churning out hundreds of thousands of datasets is just a matter of minutes for synthetic data generators. By cutting down the time taken by internal bureaucracies and data procurement, synthetic data enables enterprises to channel their time better toward the core.
Financial services company Wells Fargo takes this to the next step by testing the potential of synthetic data generators beyond datasets – they are looking into the replication of an entire database and creation of datasets for never-before-seen scenarios.
5. Bias
Tech giants like Microsoft and IBM have faced backlash for ingrained biases in their facial recognition systems. Their programs struggled to identify particular groups of people, especially if they were not white males. On the other hand, synthetic data has been found to be “fairer” than the ones generated manually.
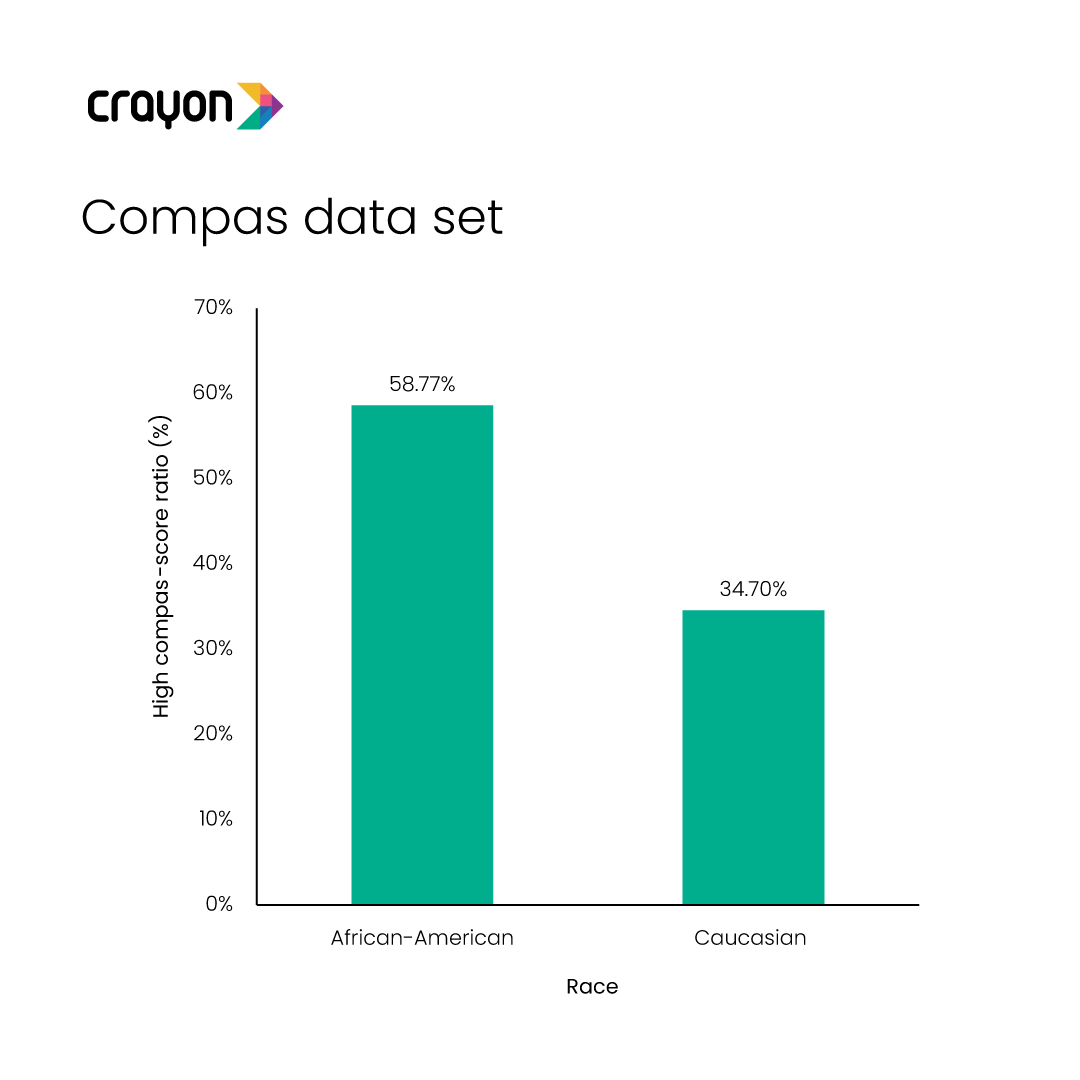
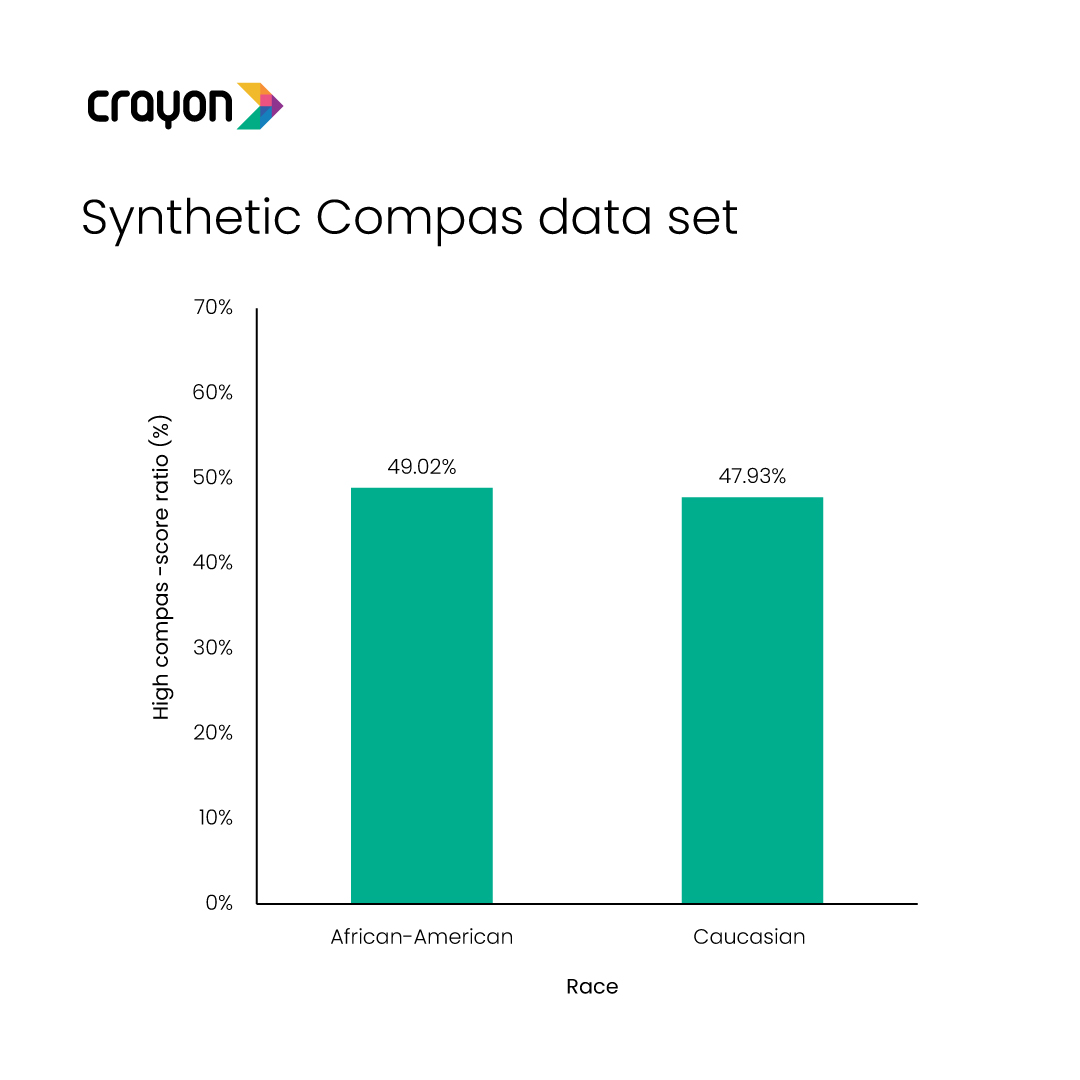
Take the case of the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS). This is a commercial algorithm that scores a criminal defendant’s likelihood of being a repeat offender. The original data sets showed that Black people were more likely to reoffend when compared to Caucasians. Mostly.AI used synthetic data to correct the skewed numbers which reflected a racial bias. The score parity for crime prediction went down from 24% to just 1 %.
The future of synthetic data generation
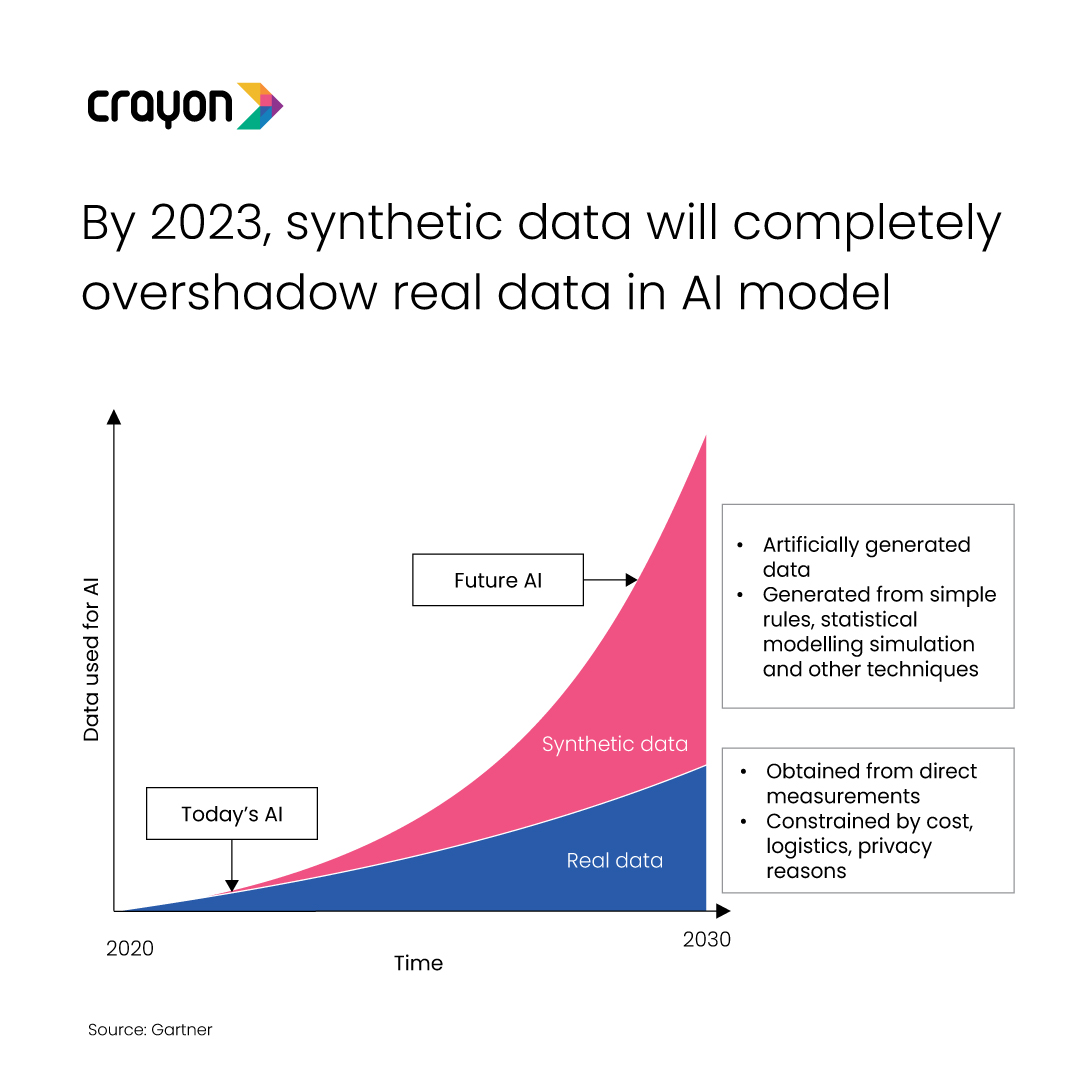
With so many potential applications, synthetic data generation is poised to become an integral part of AI models that will run the world. Research backs up our belief: Gartner predicts that by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
But data isn’t always simple.
As with any emerging technology, there are challenges aplenty.
Synthetic data is an obvious winner with the generation of simple datasets, but they aren’t great at replicating complex datasets.
While anonymization is a win for privacy issues, it may not account for outliers. Generalized synthetic data may not take these into account. These facets may add more dimensions and interesting insights.
Overtraining can result in the synthetic model reproducing data from its original data pool. Apart from skewing up the accuracy of the results, it could also cause privacy violations by revealing information from the source sets. While minimizing the effort in data preparation, enterprises may have to divert this effort towards vigilance.
These challenges are not insurmountable. They could be corrected as technology evolves. It’s up to the humans to decide.



