


With the advent of technology, people are looking for numerous ways to innovate and build products through innovation and analytics. One important example is Web Scraping with Python, which helps in the extraction of relevant data from the web.
A basis for the generation of data, it is widely used for different solutions. Python is one of the easiest and most convenient languages to code in.
With comparatively greater noise than other languages, it performs several applications, ranging from data analysis to Web Scraping.
With the Python tool named BeautifulSoup, we gather and download information that is ethically and legally shared publicly.
Most websites do not have a Web API for the extraction of their data, which can help in the ethical, legal, and easy gathering of structured data. However, using this library can prove the process to be optimal and easy.
Most websites have a file named robots.txt, which is an indication of whether scraping is permitted. This is more of a set of recommendations; hence it does not ethically or legally address this activity. However, the majority of information over the internet is already considered for public use.
What is Web Scraping?
Web Scraping or Data Scraping is the automated extraction of structured web data in a raw form. It provides one with access to public websites that do not have an API or do not provide complete access to their data. This article will help you have hands-on experience with this technology, implemented using python.
Web Scraping is generally used by businesses and individuals who look to make smart analytical decisions based on the vast amount of public data available over the internet.
Copying and pasting data over the internet is just a microscopic process of Web Scraping.
People nowadays use smarter technologies to provide a consistent and automated way of scraping data off their desired web pages. Here, we identify the process of extracting data automatically using python and its libraries.
In this tutorial, we will go through the following concepts:
- Learn about using python for scraping data from a webpage
- Use BeautifulSoup to parse HTML source code.
- Learn about Selenium as a powerful method to interact with the web page
- Extract meaningful attributes from the source code
- Request data from webpages
- Interact with the individual element using DOM manipulation and edit them as per the need
- Convert the extracted data into a structured and meaningful CSV format file
Figuring out how to extract the “exact” content
The extraction process can consist of many steps that may turn frustrating if the process is not properly followed. A good way to approach scraping would be, to begin with, scaling up by first looking up the source code of the page. A couple of methods can be employed to view the source code of the desired web page.
Using python, the .prettify command can be run on the selected soup to print the page code. However, this might print a massive amount of code, even in the case of “Error 404” pages. However, a better approach would be the use of an option called “View Page Source.” This is a more reliable way to parse through the page source code. Here, the target content selectors can be found using the simple search technique (CTRL+F).
Using Regex to identify and scrape content
These patterns can be used to search for text within a given textual input and can be implemented in python using the in-built re module. The search method can be used with our designated regular expression to find the relevant content. This is helpful, especially due to the fact source code faces a constant change. Therefore, by identifying our target data, regular expressions can help data scraping over the web.
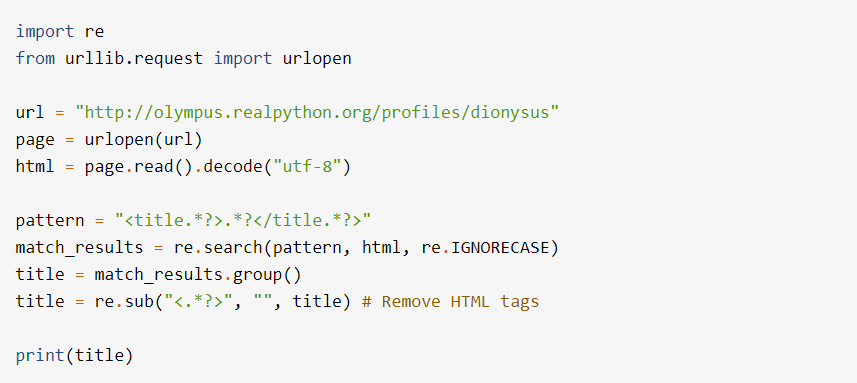
Loading and importing “request.”
This module helps in sending HTTP requests with the help of python. On calling the HTTP request, we get a Response Object in return, one that contains the response data in the form of status, encoding, content, etc. The following is an example of the same:
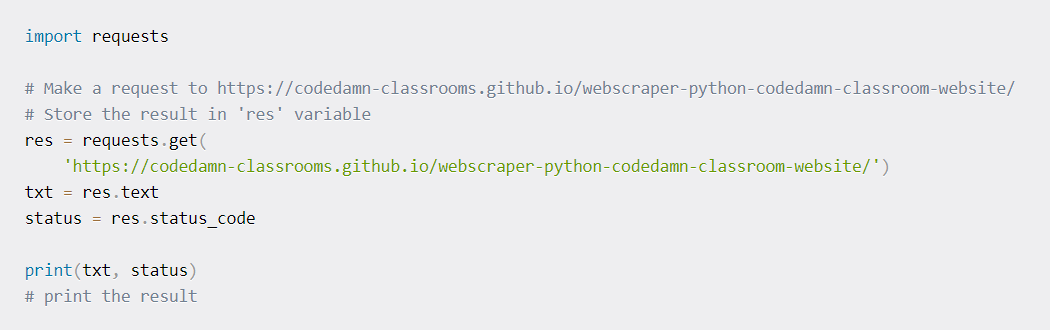
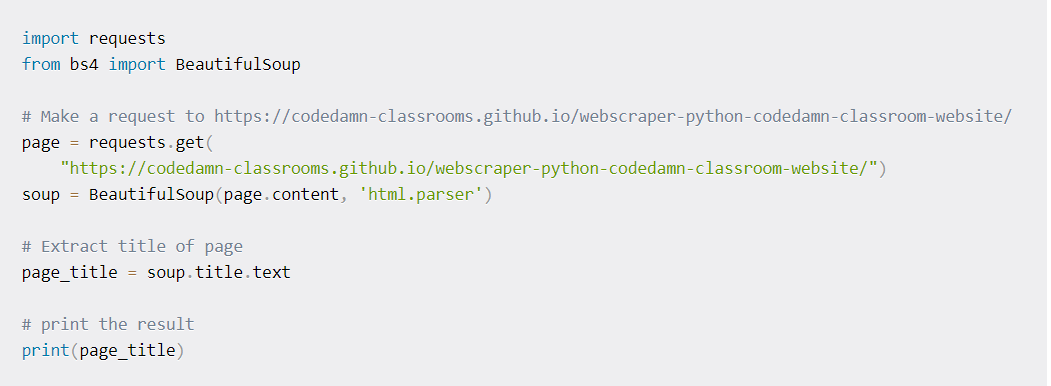
Using BeatifulSoup for the Title extraction
In this project, we will undertake a popular scraping in python, named BeautifulSoup. With minimal code, a user can easily use simple methods and idioms to modify, search, and navigate a DOM tree. One can go for flexibility on top of speed or go for various parsing strategies through parsers like html5lib and lxml. Once the page’s content is fed to the BeautifulSoup, it is easy to work with the parsed DOM tree with the help of python.
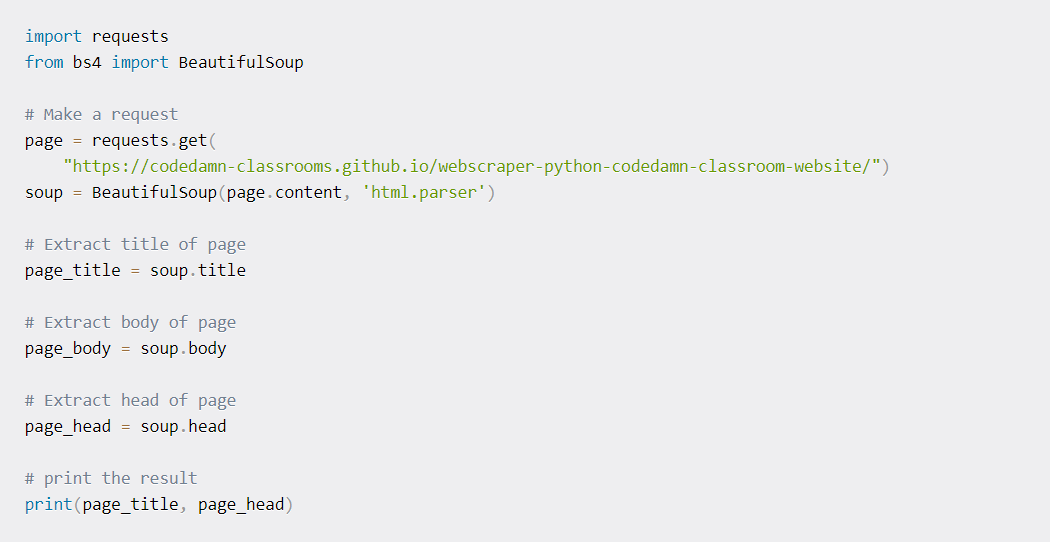
Using BeatifulSoup for the Body and Head extraction
In the last step, we extracted the title. Here, we extract other sections of the page. Printing the content without the use of .text will return the full markup. In addition to this, the body and the head are printed as strings. The following code shows how different elements of the page are selected with BeautifulSoup.
Selecting specific elements with BeautifulSoup
Once we have explored some basics of BeautifulSoup, we will now shift to selecting specific elements with CSS’s help. We first use the soup element for the page content; following this, we use the .select in a CSS Selector form. When used, this element returns all elements in the form of a Python list. Hence, the first element is accessed here with an index of [0].
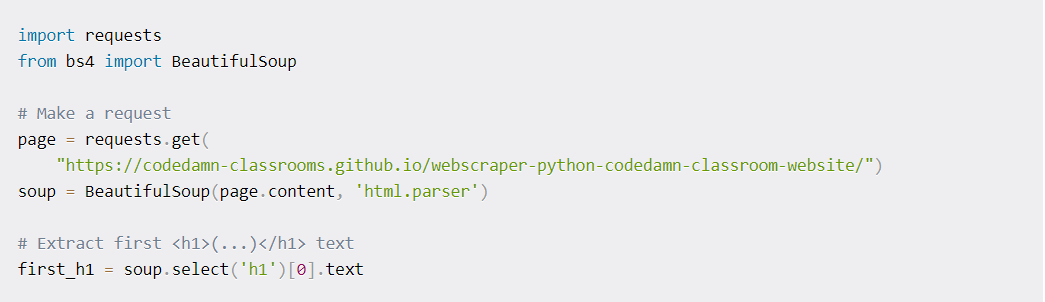
An example of scraping specific elements from the page
This example scrapes content from the website “https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/.” The task is to scrape the top items on this page. The goal is to create a new dictionary comprising of title and review for the different products available. The .select function can be used to extract titles and review count through the use of various DOM properties.
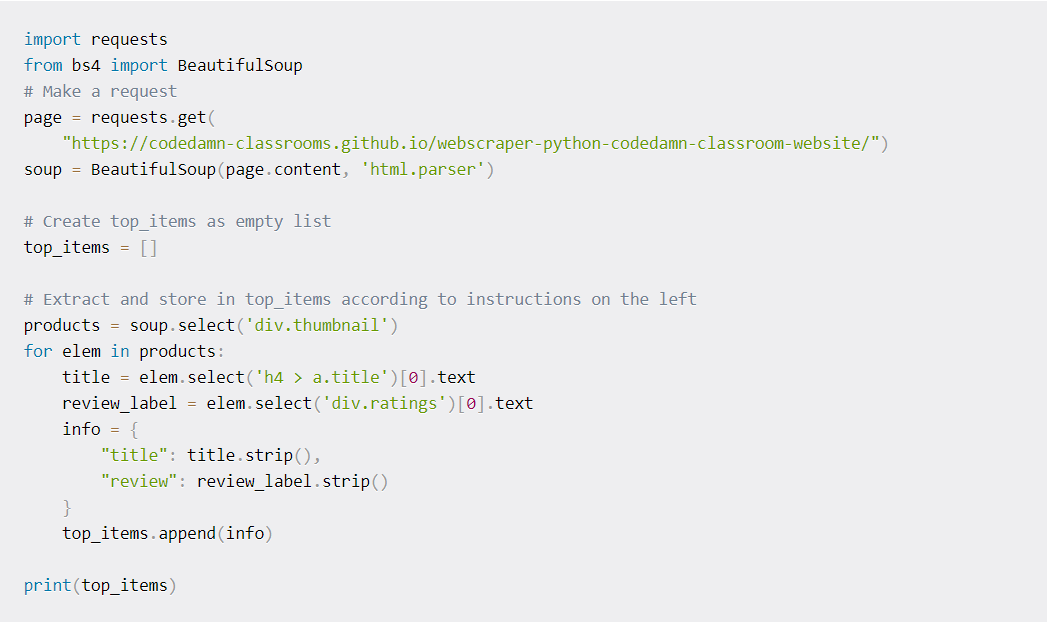
The steps to be followed are as follows. First, you have to get the list of all individual products using the div.thumbnail for the soup. With the help of select, you can iterate for different products and use it multiple times to get the title. The 0th element of the list is selected for the extraction of the text. In the end, all whitespaces and be stripped from the content and added to the list.
Extraction of Links
Now, we extract attributes by getting links from our page. Here, the href attribute can be extracted along with the text and stored in the dictionary for extraction. The process is similarly executed using the get function itself.
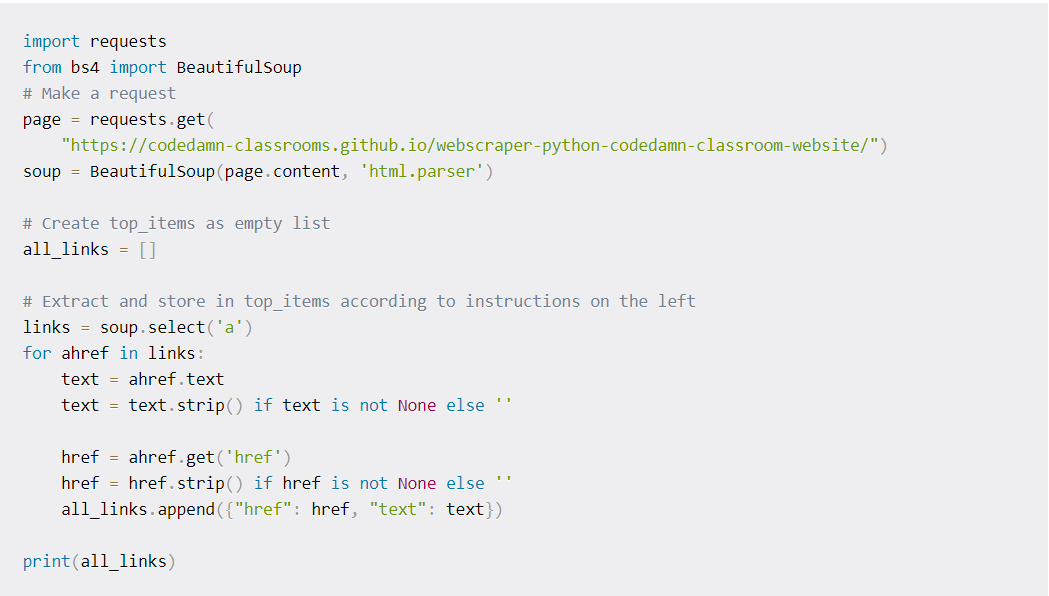
Here, it is also checked if the href attribute is None. If it None, it is set to whitespace, else stripped of whitespaces in the end.
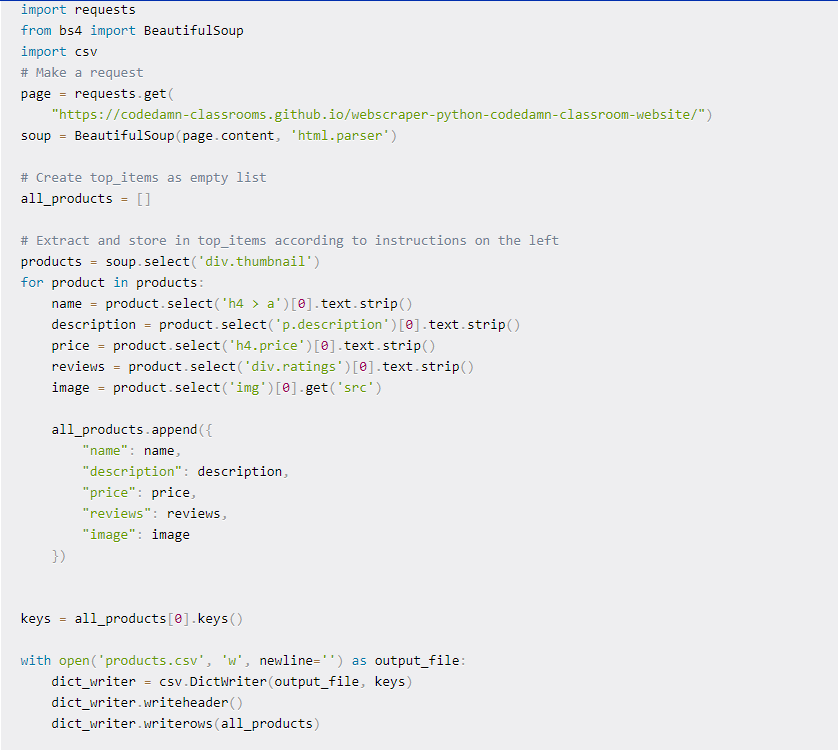
Generation of CSV from the scraped data
CSV (Comma Separated Values) is a file format used for storing structured data in a tabular form. Each row of this file corresponds to an individual data record, where each record might consist of one or more fields, all separated by commas. In this format, a comma is used as the file separator for different fields.
Once the data is scraped from the web page, we can generate the CSV for the same, each with its own set of headings. The content of the page is present in the div.thumbnail selector. As seen below, we iterate over the different title headings in this selector and generate their corresponding columns in the CSV file. This is preceded by dealing with None elements and stripping whitespace wherever required.
A brief on Selenium and Data Scraping
Selenium is an essential tool for automatically interacting with the web page. In the source code, some plugins act as modifiers, which should be accessible after the web page has loaded in the browser. This is not possible with the help of requests, only through the use of Selenium.
Selenium retrieves the content with the help of a web driver. The page content is collected after it opens the web browser itself. There are several powerful ways (Refer to the documentation for more) with which Selenium can interact with the content loaded in the browser.
Use of Pandas Dataframe for the data
Pandas can make it possible for the proper organization of our data with the application of several rules for dropping unnecessary data from the generated dataset. There are a number of operations that can be performed, such as dropping unnecessary columns.
Wrapping Up!
This was a basic step-by-step introduction of Web Scraping, from the extraction of different individual elements with the help of DOM selection, filtering, and editing, to the storage of this data in the CSV file.
In addition to this, there are other tools on PyPI that can be used for a simpler process of extraction. Just a thought, it is essential that you check with the terms of a website before proceeding with the scraping.
In addition to this, be careful to time web requests such that the server is not flooded with traffic at an instant.



