
The purpose of this article is to understand how gradient descent works. By applying and illustrating it on linear regression. We will have a quick introduction on Linear regression before jumping on to the estimation techniques.
Please feel free to skip the background section, if you are familiar with linear regression.
The reason why I chose to write on this topic is that a good understanding of gradient descent and problem formulation with a cost function, optimization objective, etc., will set a good foundation to learn advanced machine learning algorithms.
Background:
Linear regression is an approach for modeling the relationship between the dependent variable y and one or more explanatory variables denoted X.
- Based on the data, it learns a hypothesis function which fits the data well.
- This hypothesis function can be used as a predictive model for predicting y from X when y is not known.
- Data, from which the model is learned, is called labeled data, with known values of y.
- While trying to build the model any set of the list of [x1, x2, … xn] variables/features can be brought into the model.
- There can also be a set of derived variables that can be used to build the model.
Iteratively building the model and interpreting the same requires a lot of time and effort to come out with an ideal model.
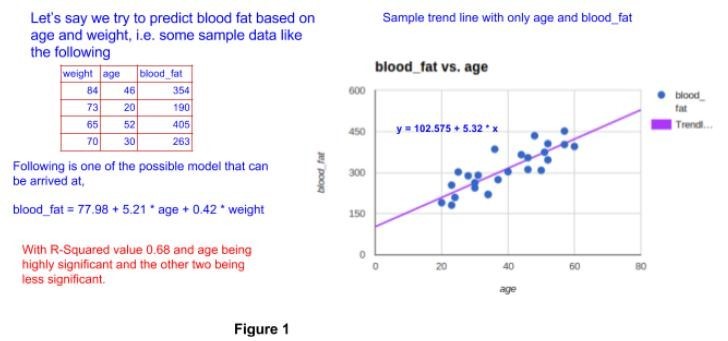
Figure 1 above shows a tiny example of a linear regression problem and possible model that can be fit.
Careful consideration is required in terms of the following while building and interpreting the model,
- Choosing the set of variables to be brought into the model
- On what form each of the variable needs to be brought in (i.e. bringing in as is or bringing in with some transformation)
- Ensuring that there is no significant correlation among the variables brought into the model
- Understanding the significance of each variable/feature part of the model built
- Creating the train and validate split to train and test/validate the model against
- Interpreting the model performance in terms of indicators like R-squared etc.
For more details on linear regression please refer to the wiki and pointers from there.
Model representation:
With the background and the example shown above. Let’s try to dive into the ways of estimating/fitting the model with the data. Let’s start with the problem formulation.

These parameters can take any possible values and the objective of the “model estimation” is to identify the best possible values that the parameters can take.

Please note that the value 1 in the feature vector X is added to include the intercept (theta_0) into the computation.
Cost function:
As mentioned above, we need to identify the best possible values of the parameters based on the given data. To achieve it, first of all, we need to define what does ‘best’ mean here. It is the criteria which decide what combination of values of the parameters are better than another combination. It needs to be quantified as well, i.e. how much better a given combination is than another one.
This criterion is defined as a cost function. You can consider it as the penalty you pay for a misprediction. Or the mistake committed by the model. Once you have arrived at the cost function, then the values of the parameters that minimize the cost function need to be computed.
In the case of linear regression, it is the squared error in the prediction that is used as the cost function. That is the deviation from the actual value of yi and the value computed from the model.
The formal mathematical representation is as follows,

Taking squared error helps us in two ways.
- It helps us take the absolute value of the deviation.
- It is easy to take the derivative of it when compared to absolute function. We will look at the use of it in the later part of the article.
Estimation techniques:
There are several ways to solve for the parameters to fit the best possible model.
Broadly there are two different classes of ways to solve this.
- One of them is called analytical or closed form solution.
- And the other one is called iterative solution (like gradient descent).
For more details around the techniques please refer to the wiki link.
Rest of the article will give an overview of the analytical solution and the gradient descent for linear regression.
Closed form solution:
Let’s simplify the cost function as something of the form,
![]()
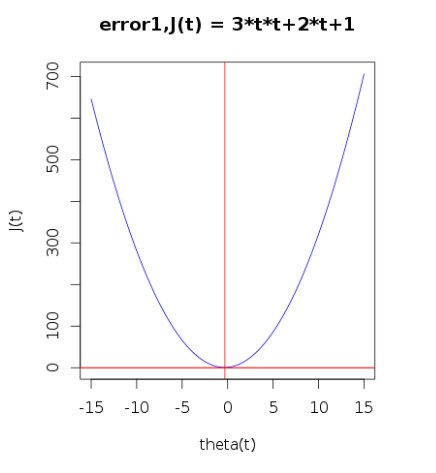
Which basically is just a single dimensional equation. If we want to minimize the value of it, we need to take the derivative of it and equate it to zero.

This can be observed from the plot below for the equation with values a=3, b=2 and c=1.

We can consider X as a matrix of dimension m x n+1, where m is the number of observations and n is the number of features. In this case, the mechanism of applying partial derivatives on all the parameters turns out to be an equation in the form,

These types of solutions are called closed form or analytical solutions. It is sometimes also called normal equations.
This solution works fine in most of the cases except in the following scenarios,

Iterative solutions:
Iterative solutions come into rescue, in these scenarios where closed form solutions fail, as mentioned above. The idea behind iterative solutions like gradient descent is to,
- Start with some initial values for the parameters and slowly move towards the local minima.
- Somehow ensure that the movement in every iteration is towards the local minima it is supposed to reach.
- Eventually figuring out when to stop iterating further and returning the solution.
Gradient descent can let the computation start with an arbitrary point and applies the following computation iteratively,
![]()
Few things to note from this equation to understand it better are,
- The partial derivative at any given point corresponds to the slope of the line that touches the curve at the given point.
- The learning rate alpha ensures that the movement/change at every iteration is a small proportion of the slope.
- Irrespective of the starting point, the sign of the slope ensures that direction of the movement towards the intended solution.
- Value of the slope reduces as we move towards the local optima and doesn’t change any further once it touches the local optima (or very close to the local optima). As the slope becomes zero in the curve on the point where the value is minimum.
- The learning rate decides, how fast the algorithm runs and converges.
All these points are illustrated below with some examples.
The plot below illustrates how gradient descent runs with the sample cost function shown above,
![]()
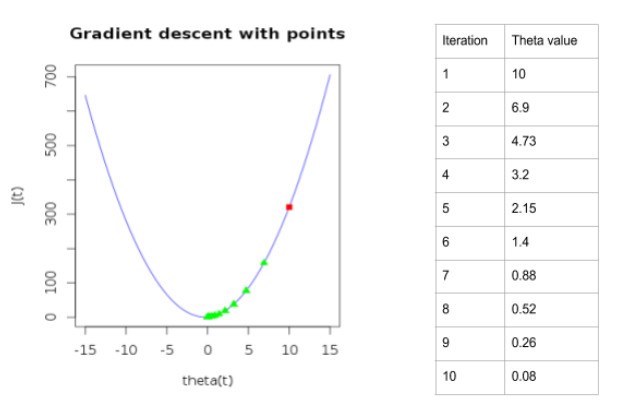
The point in red the is the starting point with theta = 10. It can be seen that, as with every iteration, it moves towards the local (global in this case) minima. Learning rate chosen here is 0.05.
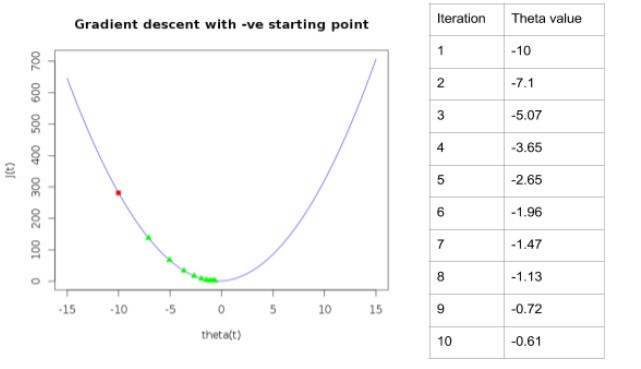
In, this case as the value of the derivative is: 6*theta+2. it will become negative in case if you start with a negative value. Hence the algorithm will move the value of theta towards positive direction (when required) in every successive iteration to reach the optimum point.
It can be observed from the plot below,
Another important thing to note would be to set the learning rate appropriately. If it is set higher, the algorithm will keep running without converging. As the values could move across minima at every iteration, instead of converging on the same.
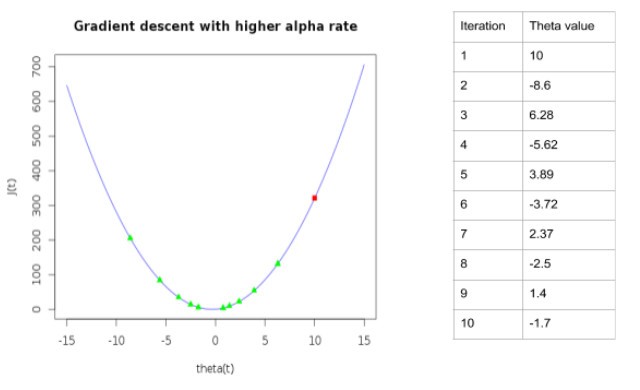
As can be seen, the values keep moving back and forth across the local minima. Hence it is critical to choose the value of learning rate appropriately.
It can also be observed that gradient descent will converge only when the function is a proper concave function (i.e. only with one global minima). Otherwise, it can get stuck to a local minima. You can consider it as a precondition for the convergence of gradient descent.
For example, from the following plot, it can be seen that the squared error cost function of the dataset shown above turns out to be a nice concave function. Hence gradient descent can be applied here to solve it.
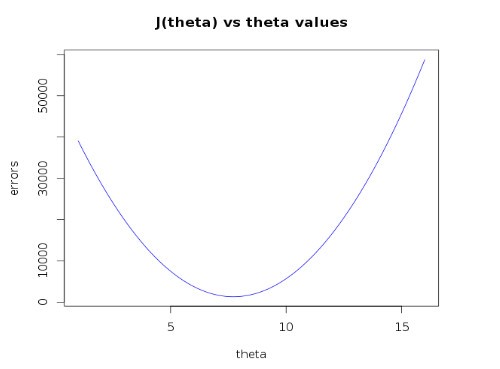
There are a couple of ways to detect when to stop the iterations,
- When the values of parameters don’t get updated beyond some minimum threshold. As it converges through global/local minima the updates will become smaller and smaller.
- Another way is to stop beyond some number of iterations.
Often times, a combination of both is used to terminate the computation, i.e. setting a minimum threshold on change and the maximum number of iterations.
The generalized algorithm for gradient descent for any dimension is as follows,

Specifically, for the squared error cost function of linear regression that we looked at earlier,

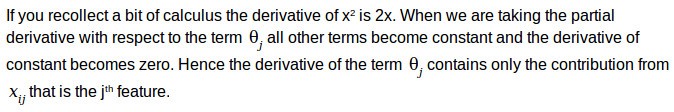
Thus, gradient descent helps us solving for the parameters, the same way we could do it with an analytical solution described earlier.
Finally, to conclude, it is mathematically nice to have a closed form solution. As it guarantees the solution always, unlike the case of gradient descent. Where the convergence depends on the starting point and the learning rate chosen.
But when it comes to huge volume of data with high dimension (i.e. large number of features), it is easy to implement a solution in a distributed environment for gradient descent, when compared to the closed form solution that we looked at.
As the closed form solution involves high dimensional matrix computations, that are hard to distribute/parallelize in some cases. Though distributed matrix operations are supported in libraries like Spark MLLib.
There are also other ways of estimations like maximum likelihood and extensions of least squared error estimations. And other ways of optimizing the iterative gradient descent algorithm.
Understanding this whole mechanism of coming out with the cost function and how to fit the parameters by minimizing the cost function, is critical to learn more complex machine learning algorithms.
If you want to play around with the code that I used to generate all these illustrations, please refer to my git hub link.



















